Dans les années 60, deux laboratoires d’informatique s’affrontent dans les murs de l’université de Stanford. Comme John Markoff l’indique dans son ouvrage, « un des deux groupes cherchait à augmenter l’esprit humain (augment the human mind), l’autre à le remplacer ». Le premier laboratoire, le Stanford Artificial Intelligence Laboratory (SAIL), souhaitait automatiser des tâches répétitives. Le second, Augmentation Research Center (ARC), dirigé par Douglas Engelbart, avait déjà prédit que l’informatique servirait à augmenter la connaissance personnelle ou le réseau personnel d’un individu. Comme au début de l’informatique, la place de l’individu dans les méthodologies de recherche d’information est de nouveau controversée.
Les premiers annuaires tels que Yahoo! étaient organisés par des humains. Pour être référencé, le Webmaster transmettait l’adresse de son site internet et une définition de son contenu. Une équipe spécialisée, engagée par l’annuaire, était en charge de valider la catégorie recommandée par le Webmaster. Google a révolutionné le secteur de la recherche en introduisant des robots (crawlers) chargés d’indexer les documents et un algorithme, le PageRank, chargé d’ordonnancer les résultats. Le succès de la firme de Richmond repose notamment sur l’efficacité de son algorithme qui s’appuie sur la structure de référencement des sites entre eux pour identifier une autorité. Mais cette structure de référencement est manipulable de deux manières (entre autres). La première consiste à afficher de nombreuses références vers un site pour faire monter sa pertinence et donc son PageRank (bombardement Google). La seconde consiste à créer des splogs (contraction des termes blogs et spam[1]), faux blogs créés par les entreprises pour mettre en avant leurs produits ou réaliser des liens vers un site en vue d’augmenter une fois encore le PageRank. Ces deux méthodes sont devenues un problème important car elles polluent l’espace de recherche des moteurs. Le contrôle de la qualité des résultats renvoyés revient donc progressivement entre les mains des utilisateurs de plusieurs manières, généralement regroupées sous le terme de « social search » ou recherche sociale.
La recherche sociale
De l’internet support à l’échange d’informations, le Web est devenu une structure fondamentalement sociale, support à la mise en relation. Ce Web « social », communément appelé Web 2.0, est constitué d’un ensemble d’applications pour produire, classer et partager des contenus, créer des réseaux relationnels et s’entraider. L’expansion d’Internet, la disponibilité de corpus composés de documents plus ou moins structurés, écrits dans diverses langues, ou la présence de contenus hétérogènes sonores ou visuels sont tous des facteurs ayant contribué à la structuration d’une communauté académique autour de la recherche d’information. Les systèmes de recherche d’information spécialisés ou les moteurs de recherche sur le Web tentent de répondre au mieux aux attentes des utilisateurs qui sont aussi variées que leurs besoins d’informations. Après une description des multiples formes que revêt ce mouvement (recherche dans des sites de confiance, entraide entre interlocuteurs, systèmes de Questions-Réponses et systèmes de recherche d’experts), nous présenterons ses justifications et limites.
La Recherche dans des sites de confiance
La première méthode consiste à fournir à l’utilisateur des ressources que lui-même ou des personnes de confiance ont déjà certifiées. Web of People de la division R&D d’Orange, My Web 2.0 de Yahoo! et Co-op de Google proposent ce type de service.
Le modèle du Web Of People déployé dans le prototype SoMeOne exploite l’intelligence distribuée des individus. L’outil permet d’organiser ses documents, sous forme de classeurs comportant des listes de diffusion administrées par l’utilisateur et s’appuyant sur une liste de contacts. L’outil fournit également un recommandeur de contacts basé sur une requête particulière. Cette approche de recherche de connaissances est particulièrement pertinente mais ne prend pas en charge la création dynamique d’un espace collaboratif support à la co-création de connaissances.
Le service Co-op de Google permet de personnaliser la liste des sites consultés par le moteur de recherche. Le choix des pages à inclure dans l’index, l’ordre de priorité du contenu et la possibilité donnée aux utilisateurs d’enrichir l’index sont également disponibles. L’internaute peut ainsi constituer son propre moteur de recherche, dans des zones qu’il a préalablement sélectionnées.
Le service My Web 2.0 de Yahoo! est relativement similaire. Il s’appuie sur le réseau social de l’individu en organisant les résultats de toutes requêtes en fonction des différents réseaux sociaux dans lesquels l’utilisateur figure. Ce service garde en mémoire les adresses des pages visitées consultées et leurs contenus afin de les partager avec d’autres grâce à une zone publique modifiable.
Au lieu de reposer uniquement sur des algorithmes pour l’efficacité de son moteur de recherche, ces trois services ajoutent une dimension sociale très riche. Néanmoins, cette dimension sociale de la recherche se limite à un contenu existant, ordonné différemment, mais ne constitue pas une méthode pour identifier de l’information non existante sur Internet ou simplement pour mettre en relation demandeurs et offreurs de connaissances.
Les Systèmes de Questions-Réponses
La recherche à travers des sites de confiance ou la recommandation de contenus par filtrage collaboratif améliorent la recherche de connaissances à travers des ressources préexistantes. Néanmoins, ces deux méthodes ne permettent pas la création de connaissances originales. C’est l’objectif que se fixent les outils de recherche sociale de deuxième génération qui, en plus de créer une audience éventuellement valorisable par le fournisseur, garantissent d’apporter une réponse à chaque requête.
Le Web 2.0 propose à chaque internaute d’être tour à tour consommateur ou contributeur sur Internet. Des outils de création de contenus simplifiés et une masse critique d’utilisateurs atteinte favorisent l’émergence d’un contexte d’entraide de type Questions-Réponses qui s’étendent parfois à la contractualisation de prestations.
Les systèmes de Questions-Réponses dont le plus emblématique est Yahoo! Questions-Réponses se distinguent des environnements présentés puisqu’ils mettent en relation un demandeur posant une question et un ou plusieurs contributeurs apportant une réponse à cette question. L’accès aux questions résolues, sous forme de base de connaissances, est disponible dans ce type d’outil mais la mise en relation entre les individus y est privilégiée.
Yahoo! Questions-Réponses
Yahoo! Questions-Réponses a été lancé en décembre 2005 et atteint 7.2 millions de visiteurs en avril 2006. Le service est très simple : s’il a accumulé assez de points, un demandeur pose une question. Des contributeurs viennent répondre à cette question. La communauté évalue chacune des questions mais le demandeur est chargé de sélectionner la réponse qu’il juge la meilleure. Ce service est devenu extrêmement populaire et le temps de réponse pour une question posée est généralement faible. Néanmoins, les questions ne sont pas automatiquement attribuées à un contributeur pertinent. Les plus simples trouvent naturellement une solution alors que les plus compliquées restent sans réponse.
Pour solutionner cette limite, des services de Questions-Réponses évoluent à travers les modèles comme celui de Yedda, Google Answer et LinkedIn.
Yedda (2007)
Yedda est assez proche de Yahoo! Questions-Réponses mais présente une différence significative : les questions sont dirigées vers des contributeurs pertinents. À l’inscription sur Yedda, l’internaute sélectionne une série de mots-clés qui l’intéressent et définissent son profil. Lorsqu’un demandeur pose une question, il sélectionne une liste de mots clés qui caractérisent sa question. La question est transmise aux destinataires pertinents ayant un ou plusieurs des mots-clés de la question compris dans son profil. Cette attribution automatique des questions améliore le simple service de Questions-Réponses mais exige une catégorisation des profils d’individus et des questions parfois délicates. De plus, ce service ne présente aucune forme d’incitation à participer, ce qui entraîne de multiples questions pour peu de réponses. Google Answer a choisi de rémunérer les réponses fournies par les contributeurs.
Google Answer et le crowdsourcing
Google Answer a été lancé en Avril 2002. Ce service est radicalement différent de Yahoo! ou Yedda puisqu’il propose d’associer à chaque question posée une rémunération (que le demandeur est disposé à verser) et une liste de contributeurs pertinents. Les contributeurs appelés « Researchers », experts de leurs domaines, sont recrutés, testés et certifiés par Google. Les autres visiteurs peuvent également laisser un commentaire, le système s’apparentant alors à un forum. Ce système de recherche sociale avec attribution des questions garantissait à minima la pertinence du contributeur sur le domaine identifié. Néanmoins, la rémunération d’activité de partage de connaissances ne semble pas être un modèle économique valable sur Internet puisque Google a arrêté ce service en décembre 2006. Cette méthode de contractualisation d’expertise est à rapprocher du phénomène de crowdsourcing qui se généralise sur le Web 2.0. Le terme « crowdsourcing » est un néologisme qui décrit l’activité d’« approvisionner par la foule » des services positionnés en dehors du cœur de métier de l’entreprise ou des compétences d’un individu. Des plateformes de mise en relation comme Mechanical Turk d’Amazon ou Wengo de Cegetel effectuent la mise en relation entre une demande et une offre de service, assurent l’intermédiation et recueillent l’évaluation de la qualité de la prestation. Cette sous-traitance permet d’externaliser des tâches très simples comme la modération de photos ou la retranscription d’entretiens faiblement rémunérées et d’autres tâches beaucoup plus sophistiquées en R&D comme le proposent Innocentives ou NineSigma. Ces méthodes sont certes efficaces mais force est de constater leur faible adoption aujourd’hui. Les outils de gestion de son réseau social qui se sont généralisés avec l’avènement du Web 2.0 constituent également une nouvelle méthode pour trouver, dans son entourage proche, des individus pertinents dans une activité de recherche de « connaissances ».
LinkedIn est un outil de gestion de son réseau social particulièrement destiné à des activités de recherche d’emploi ou de partenaires professionnels. LinkedIn s’appuie sur son audience et une fréquentation importante pour fournir un service de recherche sociale. L’outil donne la possibilité de poser une question et de la diffuser à des individus de son réseau déjà préenregistrés sur l’outil. LinkedIn propose également au contributeur potentiel de répondre aux questions qui lui sont transmises ou de les transférer vers d’autres individus de son entourage. Ce modèle de diffusion d’une question s’appuie donc sur le réseau social d’un individu et constitue, à travers LinkedIn, un espace de discussion temporaire qui se transforme en base de connaissances. Dans ce contexte, les individus semblent plus enclins à répondre à des questions provenant d’un de leurs contacts ou de leur réseau social étendu plutôt que de répondre à des questions diffusées par un inconnu sur les outils précédemment décrits.
La recherche sociale constitue donc un moyen pour pallier aux limites des moteurs de recherche. Nous recensons trois méthodes. La première consiste à naviguer sur des sites préalablement filtrés par l’internaute ou par des membres de ses groupes de référence. La seconde consiste à naviguer sur de l’information filtrée par des individus dont le profil est proche du sien. La dernière consiste à interroger des contributeurs, issus de son réseau relationnel ou suggérés par un outil et dont la contribution est rémunérée ou non. L’ensemble de ces méthodes prennent leur place dans un Internet « grand public » où les communautés sont faiblement structurées.
Les systèmes de recommandation d’experts
L’accès à la bonne information, au bon moment, est indispensable dans le monde professionnel. Les méthodes de centralisation des connaissances en place dans les organisations accusent des limites et comme l’indique Mark Ackerman, « si un être humain possédait une mémoire semblable à celle de la plupart des organisations, on le dirait atteint de troubles neurologiques ». C’est dans ce contexte précisément qu’apparaissent les systèmes de recommandation d’experts (SRE) ayant pour objectif la mise en relation entre un demandeur et un ou plusieurs offreurs de connaissances.
Les systèmes de recommandation d’experts comportent cinq macro-fonctions : « création du profil », « identification de l’expertise », « mécanismes de recherche et moteur d’association entre requête et ressource », « résultats et construction de l’information », « capitalisation, maintenance et apprentissage ».
La création du profil est le processus par lequel l’outil constitue le profil des utilisateurs. Généralement la création du profil s’effectue de manière explicite (déclaratif, par l’utilisateur ou d’autres utilisateurs le connaissant), ou de manière implicite : documents partagés, sites visités, réseaux sociaux dans lequel l’individu est actif, projets auxquels l’utilisateur a participé, utilisation récurrente de certains outils, requêtes effectuées ou réponses apportées.
L’identification de l’expertise d’un contributeur potentiel est une méta-description de l’expertise individuelle par rapport à des modèles existants.
Les mécanismes de recherche sont les processus par lequel l’outil va fournir des ressources à son utilisateur. Le processus de recherche peut s’effectuer de manière explicite à travers une requête contenant des mots-clés, en langage naturel, paramétrable socialement (par exemple, mots-clés et distance sociale des individus suggérés par l’outil) ou de manière implicite par l’observation du comportement ou de l’activité de l’utilisateur et la recommandation contextuelle de ressources.
Le moteur d’association effectue un appariement entre une requête et des ressources et s’effectuent par des techniques de recherche de connaissances ou des inférences par rapport à une requête.
Les résultats sont constitués d’informations de formes diverses, disponibles après la requête, incluant des documents, des espaces de discussions, de la connaissance préalablement capitalisée (articles), des liens vers des experts. Les experts peuvent être classés par ordre de pertinence et selon des critères de compétences ou des critères sociaux. La pertinence d’un individu est notamment sociale, par conséquent des outils intègrent un instrument de collecte d’information (votes, évaluations…) sur la qualité des participations.
La construction de l’information est le processus par lequel l’outil fournit un espace d’échange et de création de l’information. Certains outils proposent uniquement les coordonnées d’autres utilisateurs satisfaisant une requête. Pour d’autres outils, la mise en relation entre demandeur et offreur(s) de connaissances s’accompagne de la création d’un espace collaboratif.
La capitalisation de l’information est le processus par lequel les connaissances construites à travers l’outil ou dans l’interaction sont capitalisées et rendues disponibles pour un usage ultérieur. Maintenance et apprentissage sont les processus par lesquels, de manière transparente ou non, l’outil s’enrichit au fur et à mesure qu’il affine les profils des utilisateurs.
Après avoir décrit fonctionnellement les systèmes de recommandation d’experts, nous allons détailler quelques solutions existantes et les limites qu’elles présentent.
Responsive
Responsive (Belin et Bertrand, 2006) est un projet de Social search, en entreprise, proposé par la division R&D d’Orange. L’outil s’apparente à un service de messagerie instantanée doté de la possibilité d’ajouter des tags (annotations sémantiques) aux questions posées ou aux individus que l’on contacte. L’individu qui pose sa question la diffuse à une liste de destinataires qu’il juge capable d’y répondre, ou susceptible de connaître quelqu’un capable d’y répondre. La diffusion de la question au sein du réseau social augmente la probabilité d’obtenir des réponses pertinentes faisant bénéficier non seulement le demandeur mais également l’ensemble de la communauté. La diffusion de la question peut être confidentielle (privée) ou élargie. Cette approche présente néanmoins une limite : un réseau social de départ doit être tissé et l’individu isolé ne saura pas vers quels destinataires transférer sa requête.
Agilience
Agilience est un système de recommandation d’experts s’appuyant sur la messagerie électronique pour la création du profil de l’utilisateur et la recherche de connaissances ou d’individus. Dans la phase d’apprentissage, les messages électroniques envoyés sont analysés. Les mots les plus significatifs sont comparés à une taxonomie, suggérée par Agilience, et extraits pour constituer le profil de l’utilisateur. Ce profil reste entièrement maîtrisé par l’utilisateur qui ajoute ou supprime des mots significatifs de son activité ou d’autres devant rester confidentiels. Dans la phase de recherche de connaissances ou de recherche d’experts, l’individu envoie un message électronique avec le libellé de sa requête. La syntaxe du message est interprétée par Agilience et comparée à la taxonomie du système. Sur la base de cette analyse, le système de recommandation renvoie, par messagerie électronique, trois types d’informations :
? une liste de documents pertinents,
? une liste d’individus pertinents,
? une liste d’individus relais (capables de rediriger la requête).
L’utilisateur du système peut consulter les documents suggérés ou contacter les individus pertinents. Agilience utilise les requêtes transmises ou répondues pour affiner le profil des utilisateurs.
S’appuyant entièrement sur la messagerie électronique, Agilience constitue une solution transparente et facilement déployable. Ce modèle présente une limite : Agilience envisage l’échange entre demandeur et offreurs de connaissances comme un processus bilatéral. La coopération entre plusieurs offreurs de connaissances, associée à la création d’un espace dédié et capitalisable n’est pas envisagée. Dans un environnement professionnel où la connaissance est distribuée entre individus et où la validation s’effectue généralement entre pairs, les outils de recommandations d’experts doivent proposer des espaces ouverts d’échanges d’informations.
Referral Web
Referral Web est un système de recommandation d’experts créé dans le laboratoire d’AT&T. La cartographie du réseau social différencie particulièrement cet outil d’autres systèmes de recommandations d’experts. Le profil des individus se constitue à partir de mots-clés extraits sur des pages Internet et des documents partagés où le nom de l’individu figure. Le réseau social est également dessiné à partir de la cooccurrence de noms sur des publications scientifiques, des organigrammes et tous documents publics. L’individu utilisant Referral Web choisit la portée de sa requête, distance qui sépare le demandeur des offreurs de connaissances. Cet outil est particulièrement intéressant pour la création transparente du profil de l’individu et son positionnement dans un réseau social. Néanmoins, cet outil est concentré exclusivement sur la recommandation d’individus. Le processus d’échange et de construction collaborative de réponses à une requête n’est pas supporté par cet outil, confiné à un rôle d’intermédiation.
Answer Garden 2
Answer Garden 2 s’appuie sur un système multi-agent qui sélectionne le destinataire d’une requête. Les concepteurs de ce système insistent sur l’importance de transmettre une réponse au cercle géographique ou professionnel restreint, élargissant ainsi progressivement le cercle de diffusion d’une requête (notion d’escalade dans la portée de la diffusion). Mais, malgré la possibilité de rendre anonyme sa requête ou sa réponse, l’utilisateur d’AG2 ne maîtrise pas les destinataires.
BuddyFinder
BuddyFinder est un système de recommandation d’experts réalisé par l’Open University en Angleterre. Ce SRE constitue un profil utilisateur à partir de mots clés déclarés par l’utilisateur ou de pages Internet pertinentes dans la description de son profil. Le demandeur ajoute BuddyFinder dans ses contacts et l’interroge par messagerie instantanée. L’outil renvoie une liste d’individus pertinents dont le profil comprend un ou plusieurs mots clés. L’utilisateur peut également mettre à jour son profil par messagerie instantanée. En s’appuyant presque exclusivement sur la messagerie instantanée pour gérer le profil ou rechercher un contributeur pertinent, BuddyFinder s’inscrit dans les pratiques des utilisateurs. Néanmoins, cet outil souffre de la même limite qu’Agilience : il ne permet pas la création d’un espace collaboratif dédié dans lequel plusieurs individus peuvent élaborer de manière commune une réponse.
Nous venons de décrire une série de solutions présentes sur Internet ou dans l’entreprise et partageant l’objectif d’une amélioration de la recherche d’information par une action collective. Force est de constater la cristallisation de réseaux sociaux autour de services Internet comme Facebook ou LinkedIn, réseaux sociaux réutilisables pour le « Social search » notamment.
Cette description est brièvement résumée dans le Tableau 1.
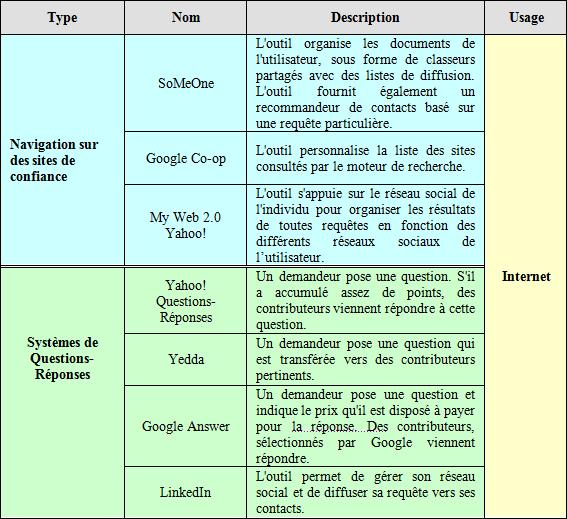
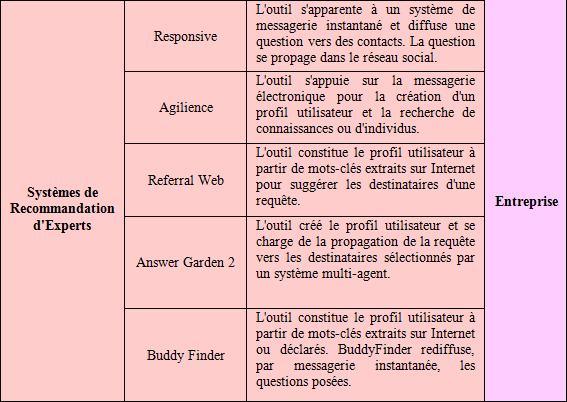
Tableau 1. Solutions disponibles pour la recherche sociale
Article co-écrit par Charles DELALONDE & Stéphane ROUILLY (EDF R&D)
[1] Voir l’article « More Spim than Spam », L’année des TIC 2005.